Algorithms as Data Sources
This post describes a feature the v1 engine. Our v2 engine's handling of child algorithms is much cleaner.
TuringTrader supports a variety of data feeds to bring in quotes and other data. But often it is more natural to describe data in algorithmic form. With our latest feature, you can do just that: use an algorithm as a data source.
Sub-classable Algorithms
At the core of the new feature is a new base class, SubclassableAlgorithm. This class is just like the regular Algorithm base class, with some added features:
- ability to receive simulation start and end times from a parent object
- ability to create bars, and push add them to a parent object
Now when it comes to writing a sub-classable algorithm, everything is pretty much the same as with regular algorithms, with only very few new concepts.
First, sub-classable algorithms must be derived from the new base class:
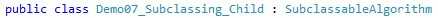
Next, we should check if we received simulation time frames from a parent. If so, we should probably use these; otherwise, we are free to set our own:

Now we are ready to run the simulation. Inside our simulation loop, we can create bars, and add them to the data source as we see fit. We are sure you can come up with something more useful than this example:

That’s it! We have now successfully created an algorithm, which feeds into a data source. It is important to point out that a sub-classable algorithm can be run both stand-alone and as the child of a data source. Depending on your use-case, it might be a good idea to create a helpful report, just like you would for any other algorithm.
Using Algorithms as Data Source
Once we have created our sub-classable algorithm, using it as a data source is trivial: it is no different from using any other data source. All we need to do is to add a data source with the proper nickname. In this case, the nickname is the algorithm’s class name, prefixed with “algo:”:
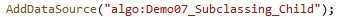
To further detail this, we have created the new Demo07. As always, you can find the full source code in the repository.
But what do we need this for? The possibilities are endless. Here are just some examples of how we use this feature:
- For benchmark purposes, we needed a data source representing a passive 60/40 portfolio — nothing easier than that, using an algorithm as a data source.
- The FRED database publishes data independent from market trading days. However, it is easier to process the data in the event loop when they are aligned with our market data. We used a sub-classable algorithm to clean this up.
- Leveraged inverse ETFs were introduced around 2008. We wanted to backtest further, and modeled these quite realistically from the S&P total return index. With algorithms a data source, these models become drop-in replacements for the ETFs.
- Bond ETFs are around since 2002. We modeled them much further back, using available yields and a little bit of math. Now we can drop these models into algorithms the same way as ETFs.
We are sure you can come up with plenty of other use cases.
Happy coding!